When you think about Google Cloud (yes, Google Cloud, not GCP please!), you think about Big Query right?. What about Azure? That’s Active Directory and Microsoft corp stuff. And AWS? EC2 and tons of infrastructure services.
Each cloud provider has its own reputation, and clichés, but there’s one Google Cloud service that I really fell in love when I was working at Google, and that rarely gets mentioned outside of its users (like me): Cloud Run.
FaaS vs CaaS: two different approaches
Before we talk about my favorite Google Cloud product: Cloud Run, let’s clarify what serverless actually means. There are two main types:
FaaS (Function as a Service) like AWS Lambda or Azure Functions. You write individual functions, and the platform runs them when triggered. Each function is isolated, has size limits, and runtime restrictions. You need to split your app into small pieces.
CaaS (Container as a Service) - you package your entire app in a container, and the platform runs it. No splitting required, no runtime limitations. If your container works locally, it works in production.
Cloud Run is primarily CaaS. But Google also merged Cloud Functions into Cloud Run as “Cloud Run Functions” (still with me?). Now when you deploy a function, it automatically containerizes your code and runs it on Cloud Run infrastructure. So technically, Cloud Run handles both approaches, but its core strength is running containers.
Lambda made FaaS popular. Netflix and Amazon pushed microservices everywhere. Now everyone thinks serverless means splitting your app into 47 different Lambda functions.
But this doesn’t work for everyone.
When you’re building a side project, testing an idea, or your startup needs to ship quickly, you just want to build a monolith, put it in a container, and deploy it. Then you’re stuck with these options:
- Deploy a VM (EC2, GCE, Azure VM) -> you need to install Docker, manage updates, and pay for resources even when nobody uses your app
- Use Kubernetes -> way too complicated, expensive, and you need to manage everything (you don’t have yet a team of 25 SREs…)
- Use Lambda functions -> you need to refactor your entire app, manage orchestration, and debugging becomes really painful
Cloud Run solves this problem
Cloud Run is CaaS by default (and can be FaaS, yes the service will just containerize your code, as explained few lines above). You push your container, it scales automatically, and you only pay when someone actually uses it.
No servers to manage. No Kube configuration (please, god, no k8s for small projects). No need to refactor your app into functions.
That’s it. Serverless for containers (even if you’ve just pushed code).
Why people don’t know about it
I don’t have an exact answer, but maybe because Google Cloud is known for being EXCELLENT when it comes to data stuff.
When people need infrastructure, they go to AWS. When they need enterprise tools, they go to Azure. When they need data, they go to Google Cloud, and what a mistake…
Cloud Run doesn’t fit in this picture, so people miss it, even if I must admit that lot of Google Cloud customers are using CR as part of their ETL/ELT pipelines.

And that’s too bad, because for a lot of small to medium projects, it’s actually the best option, far from your average vm…
6 ways Cloud Run simplifies my daily projects
1. It scales to zero without the pain
When nobody uses your app, Cloud Run scales to zero instances. You pay NOTHING, zero. Most serverless platforms do this, but cold starts can be a problem. With Cloud Run, you’re usually looking at 100-300ms, though it varies depending on the app, the runtime, etc.
The reason is gVisor. Cloud Run uses it for container isolation instead of full VMs. When a request comes in, the container doesn’t boot from scratch. The runtime is already there, Cloud Run just restores your application state. You also get a CPU boost during startup (can be up to 2x your configured CPU), so your init code runs faster.
If you really need guaranteed response times, you can set minimum instances. Keep one instance always warm, let the rest scale to zero. As you will keep active resources, you will pay for this “inactive” instance resources. But you will get sub-100ms response times without paying for a huge capacity elsewhere.
2. Long requests work out of the box
Most FaaS platforms have strict timeout limits. Cloud Run goes up to 60 minutes per request.
But there’s more than just the timeout. Cloud Run supports HTTP/2 and gRPCnatively. You can stream responses, handle websockets, keep connections open for server-sent events. On traditional FaaS platforms, you need API Gateway for HTTP, and getting websockets or streaming to work requires workarounds.
The request timeout is configurable per service. Need 5 minutes? Set it. Need 60? Set it. You’re not stuck with a platform-wide limit. And since Cloud Run uses standard HTTP, testing locally with Docker works exactly like production.
3. Use any container you want
Traditional FaaS platforms have specific runtimes, package size limits (often around 250MB unzipped), and restrictions on what you can install. Cloud Run takes your Dockerfile and runs it. That’s it.
Your container size doesn’t matter. The only limitation will come from your registry (with Artifact Registry, it’s 5TB - but don’t even think about it please). You can install system dependencies, compile native extensions, bundle large ML or small AI models, and much more. Need a specific Python version with custom C extensions? Fine. Want to run a Rust binary? Works.
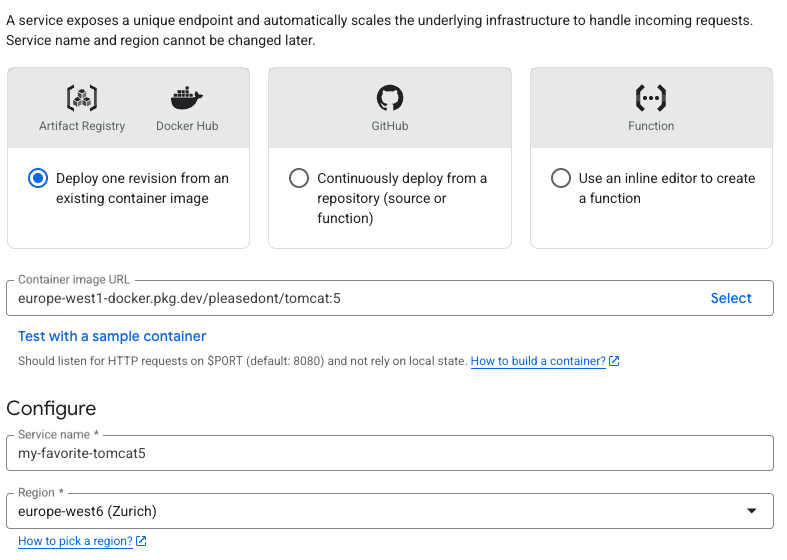
Cloud Run pulls your container from Artifact Registry (or any other registry) and caches it. Deployments are fast because only changed layers transfer. And because it’s just a container, you run the exact same image locally, in CI, and in production. No more “works on serverless but not locally” problems.
4. Private network without the complexity
Connecting serverless to a private database often means VPC configuration, NAT Gateways, and cold starts that can be tricky to manage.
Cloud Run is simpler. Enable VPC egress in one click, specify your VPC network. Your container gets a vNIC to your VPC. Cloud SQL? Direct connection via the Cloud SQL Auth Proxy or private IP. Memorystore Redis? Just use the internal IP. No NAT, no bastion, no VPN.
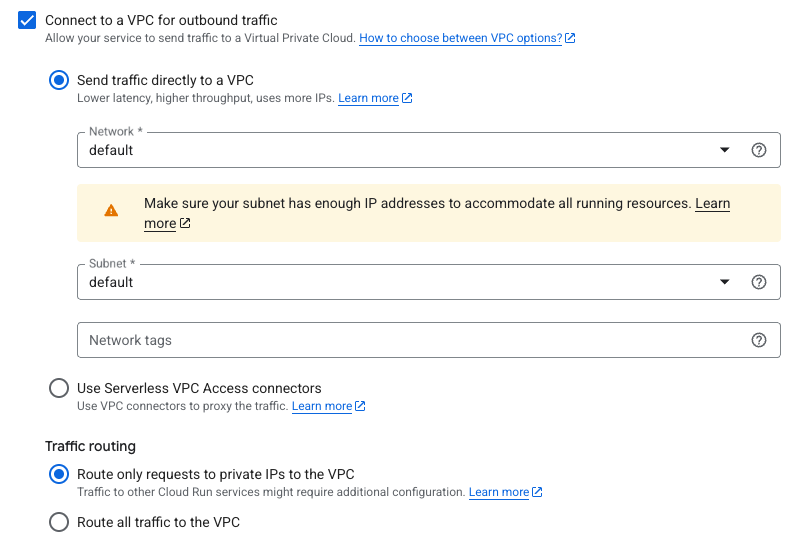
The cold start penalty is small because Cloud Run doesn’t attach ENIs at runtime. The network interface is part of the container environment from the start. And if you need external APIs, you can still call them without routing everything through a NAT Gateway.
5. You pay for what you use
With Cloud Run, you are billed for what you use, rounded up to the nearest 100 milliseconds. CPU and RAM are separate settings. API that responds in 50ms with 512MB RAM? That’s what you pay for.
There’s also two CPU allocation modes. “CPU only during request processing” means you pay for CPU only when handling requests. “CPU always allocated” lets your container run background tasks between requests.
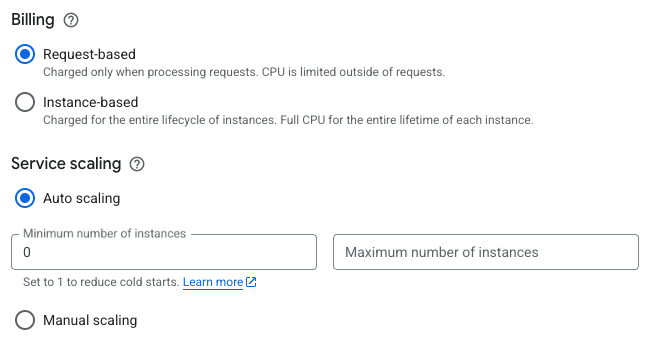
Memory pricing is linear. Pick 128MB, 512MB, 2GB, 8GB - whatever you need. CPU goes from 0.08 vCPU to 8 vCPU in small increments. You can profile your app and set exactly what it needs to optimize cost per request.
On most FaaS platforms, CPU and RAM are linked together. Want more CPU? You also get more RAM whether you need it or not. Cloud Run lets you tune both independently, except on some specific cases (max CPU/RAM or GPU attachment).
6. Serverless GPU support
Since summer 2025, GPU support in Cloud Run is available. You get per-second billing for GPUs, and there’s no additional cold start penalty. Once your container is up, the GPU is already there and ready.
Need to test a small LLM without breaking the bank? Deploy it on Cloud Run with a real GPU. You pay only when someone actually uses it. No need to keep an expensive GPU instance running 24/7 just for occasional inference requests.
NVIDIA L4 with 24GB VRAM is the GPU model currently available. The only limitation is that you can attach one GPU per container. Same story as CPU and RAM, you configure what you need, and you pay for what you use.
This opens up interesting use cases. Real-time image processing, video transcoding, ML inference on demand. All serverless, all billed per second. No Kubernetes cluster to manage, no GPU nodes to provision.
In the next episode…
This was the first part of my blog post on Cloud Run and CaaS. I plan to release 2 or 3 parts in total. In the next article, I’ll share benchmarks comparing it to existing competitors, discuss a simple migration path to Kubernetes (ONLY for projects reaching significant scale please), the HUGE free tier offered by Google, some limitations (because the perfect product doesn’t exists) and go over the other cool options I haven’t covered here.